A handy feature of Hadoop Hive is the ability to use the filename and path of underlying files as columns in a view or table using the virtual Hive column INPUT__FILE__NAME. This is particularly handy in the case of external tables where some metadata about files is embedded in the location on HDFS or the filename itself.
The problem
Say we have some files sitting under a nested folder structure in HDFS:
[hdfs@sandbox ~]$ hadoop fs -ls -R /tmp/testonly/ drwxr-xr-x - hdfs hdfs 0 2016-03-06 14:08 /tmp/testonly/nsw -rw-r--r-- 1 hdfs hdfs 16 2016-03-06 14:08 /tmp/testonly/nsw/2016-01-01.txt -rw-r--r-- 1 hdfs hdfs 16 2016-03-06 14:08 /tmp/testonly/nsw/2016-01-02.txt drwxr-xr-x - hdfs hdfs 0 2016-03-06 14:08 /tmp/testonly/vic -rw-r--r-- 1 hdfs hdfs 16 2016-03-06 14:08 /tmp/testonly/vic/2016-01-01.txt drwxr-xr-x - hdfs hdfs 0 2016-03-06 14:08 /tmp/testonly/wa -rw-r--r-- 1 hdfs hdfs 16 2016-03-06 14:08 /tmp/testonly/wa/2016-01-02.txt
The files each contain two columns, a string and an integer. We can create an external hive table as follows:
CREATE EXTERNAL TABLE default.test_filename ( col0 string, col1 int ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '/tmp/testonly/';
A simple select on the above table shows data from all subdirectories without any more information:

The solution – including file metadata in Hive
Hive features a virtual column INPUT__FILE__NAME which can be used to query the file location and filenames of textfiles where the actual table data is sitting:
SELECT INPUT__FILE__NAME, * FROM default.test_filename;
The full HDFS path is now included as a column in each row of data (e.g. “hdfs://sandbox.hortonworks.com:8020/tmp/testonly/vic/2016-01-01.txt”):
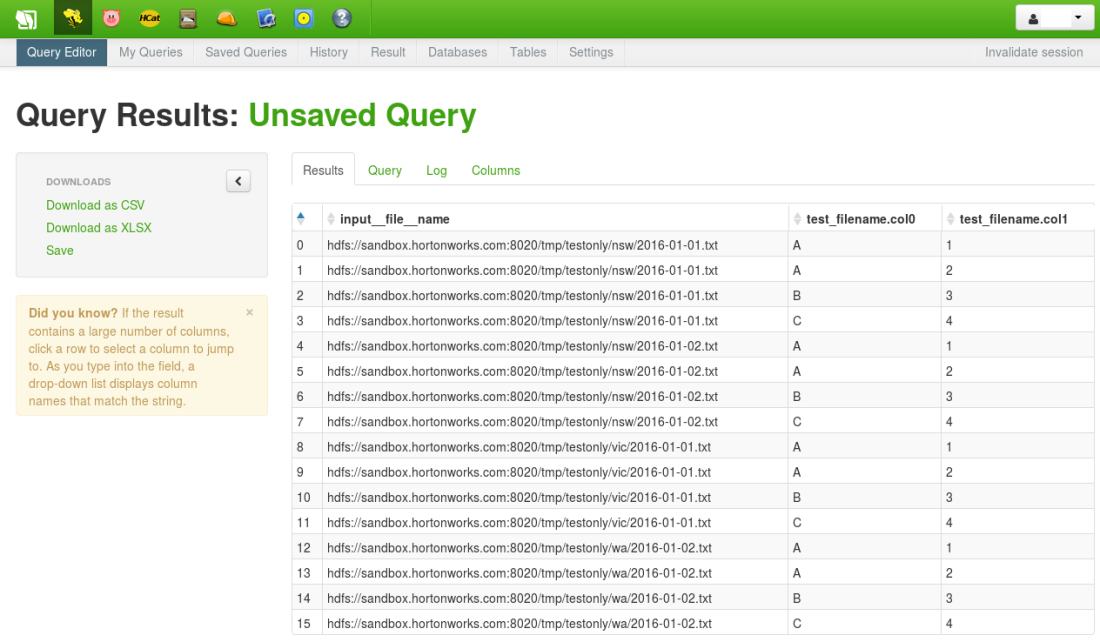
We can go one step further and use standard Hive functions to create two new artificial columns – file_date (from the filename) and state (from the HDFS subfolder).
SELECT substring(INPUT__FILE__NAME,length(INPUT__FILE__NAME)-13,10) as file_date, regexp_extract(INPUT__FILE__NAME, '.*/(.*)/.*.txt', 1) as state, * FROM default.test_filename;
Now there are two extra columns in our Hive resultset derived solely from the HDFS path of the underlying files:

