The Hive metastore stores metadata about objects within Hive. Usually this metastore sits within a relational database such as MySQL.
Sometimes it’s useful to query the Hive metastore directly to find out what databases, tables and views exist in Hive and how they’re defined. For example, say we want to expose a report to users about how many Hive tables are currently in a Hadoop cluster. Or perhaps we want to run a script which performs some bulk operation on all tables in a particular Hive database.
Luckily, it’s easy to query the metastore using a tool such as MySQL Workbench using appropriate connectors – e.g. MySQL JDBC drivers.
Here’s a rough database diagram showing how the Hive metastore hangs together:
Hive metastore database diagram (from HDP 2.3, click here for full screen)
SELECT t.* FROM hive.TBLS t
JOIN hive.DBS d
ON t.DB_ID = d.DB_ID
WHERE d.NAME = 'default';
Output:
TBL_ID
CREATE_TIME
DB_ID
LAST_ACCESS_TIME
OWNER
RETENTION
SD_ID
TBL_NAME
TBL_TYPE
VIEW_EXPANDED_TEXT
VIEW_ORIGINAL_TEXT
LINK_TARGET_ID
1
1439988377
1
0
hue
0
1
sample_07
MANAGED_TABLE
NULL
NULL
NULL
2
1439988387
1
0
hue
0
2
sample_08
MANAGED_TABLE
NULL
NULL
NULL
Show the storage location of a given table
SELECT s.* FROM hive.TBLS t
JOIN hive.DBS d
ON t.DB_ID = d.DB_ID
JOIN hive.SDS s
ON t.SD_ID = s.SD_ID
WHERE TBL_NAME = 'sample_07'
AND d.NAME='default';
SELECT t.* FROM hive.TBLS t
JOIN hive.DBS d
ON t.DB_ID = d.DB_ID
WHERE TBL_NAME = 'vw_sample_07'
AND d.NAME='default';
Output:
TBL_ID
CREATE_TIME
DB_ID
LAST_ACCESS_TIME
OWNER
RETENTION
SD_ID
TBL_NAME
TBL_TYPE
VIEW_EXPANDED_TEXT
VIEW_ORIGINAL_TEXT
LINK_TARGET_ID
31
1471788438
1
0
hue
0
31
vw_sample_07
VIRTUAL_VIEW
select count(*) from `default`.`sample_07`
select count(*) from default.sample_07
NULL
Get column names, types and comments of a given table
SELECT c.* FROM hive.TBLS t
JOIN hive.DBS d
ON t.DB_ID = d.DB_ID
JOIN hive.SDS s
ON t.SD_ID = s.SD_ID
JOIN hive.COLUMNS_V2 c
ON s.CD_ID = c.CD_ID
WHERE TBL_NAME = 'sample_07'
AND d.NAME='default'
ORDER by INTEGER_IDX;
Output:
CD_ID
COMMENT
COLUMN_NAME
TYPE_NAME
INTEGER_IDX
1
NULL
code
string
0
1
NULL
description
string
1
1
NULL
total_emp
int
2
1
NULL
salary
int
3
Conclusion
It’s possible to query metadata from the Hive metastore which can be handy for understanding what data is available in a Hive instance. It’s also possible to edit this information too, although this would usually be inadvisable as the schema of the metastore may be subject to change between different Hive versions, and the results of modifying Hive internals could be unexpected at best, and catastrophic at worst.
Working with Hive can be challenging without the benefit of a procedural language (such as T-SQL or PL/SQL) in order to do things with data in between Hive statements or run dynamic hive statements in bulk. For example – we may want to do a rowcount of all tables in one of our Hive databases, without having to code a fixed list of tables in our Hive code.
We can compile Java code to run queries against hive dynamically, but this can be overkill for smaller requirements. Scripting can be a better way to code more complex Hive tasks.
Python to the rescue
Python code can be used to execute dynamic Hive statements, which is useful in these sorts of scenarios:
Code branching depending on results of a Hive query – e.g. ensuring Hive query A successfully executes before running Hive query B
Using looked-up data to form a filter in a Hive query – e.g. selecting data from the latest partition in a Hive table without needing to perform a nested query to get the latest partition
There are several Python libraries available for connecting to Hive such as PyHive and Pyhs2 (the latter unfortunately now unmanaged). Some major Hadoop vendors however decline to support this type of direct integration explicitly. They do, however, still strongly support ODBC and JDBC interfaces.
Python + JDBC
We can, in fact, connect Python to sources including Hive and also the Hive metastore using the package JayDeBe API. This is effectively a wrapper allowing Java DB drivers to be used in Python scripts.
Example:
The shell code (setting environment variables)
First, we need to set the classpath to include the library directories where Hive JDBC drivers can be found, and also where the Python JayDeBe API module can be found:
A metastore query can be run to retrieve the names of all tables in the default database into an arry (mysql_query_output):
# Query the metastore to get all tables in defined databases
mysql_query_string = "select t.TBL_NAME
from TBLS t join DBS d
on t.DB_ID = d.DB_ID
where t.TBL_NAME like '%mytable%'
and d.NAME='default'"
curs_mysql.execute(mysql_query_string)
mysql_query_output = curs_mysql.fetchall()
Hive queries can be dynamically generated and executed to retrieve row counts for all the tables found above:
# Perform a row count of each hive table found and output it to the screen
for i in mysql_query_output:
hive_query_string = "select '" + i[0] + "' as tabname,
count(*) as cnt
from default." + i[0]
curs_hive.execute(hive_query_string)
hive_query_output = curs_hive.fetchall()
print hive_query_output
Done! Output from Hive queries now should be printed to the screen.
Pros and cons of the solution
Pros:
Provides a nice way of scripting whilst using Hive data
Basic error handling is possible through Python after each HQL is executed
Connection to a wide variety of JDBC compatible databases
Cons:
Relies on client memory to store query results – not suitable for big data volumes (Spark would be a better solution on this front, as all processing is done in parallel and not brought back to the client unless absolutely necessary)
Minimal control / visibility over Hive query whilst running
Hive comes with some handy functions for transforming dates. These can be helpful when working with date dimension tables and performing time-based comparisons and aggregations.
e.g. Convert a native Hive date formatted date string:
date_format(myDate,'dd-MM-yyyy')
Return the week number (within the year) of a particular date – i.e. first week of the year is 1, the week of new year’s eve is 52, etc:
weekofyear(myDate)
Other less obvious examples
Current month’s name (e.g. January, February, etc):
date_format(myDate, 'MMMMM')
First date of the current quarter:
cast(trunc(add_months(myDate,-pmod(month(myDate)-1,3)),'MM') as date)
Last date of the current quarter:
cast(date_add(trunc(add_months(myDate,3-pmod(month(myDate)-1,3)),'MM'),-1) as date)
Day number of the current quarter (e.g. April 2nd is day 2 of the second quarter, December 9th is day 70 of the fourth quarter, etc):
datediff(myDate,cast(trunc(add_months(myDate,-pmod(month(myDate)-1,3)),'MM') as date))+1
Hadoop Hive features several useful functions for efficiently performing analytics over ordered sets of rows — these are known as the windowing and analytics functions. For example, lead and lag functions can be used to produce rolling averages or cumulative sums over a window of time (e.g. hourly averages for some metric over the preceeding rolling 24 hours).
Another useful feature is the ability to introduce ordinality or sequence into SQL data where there is no strict or predictable sequence field. This can help us search for chains of events over time.
Example
Imagine a supermarket tracking customer purchases. The following query can be used to find customers who have purchased an Apple in one transaction and in their immediate next transaction, an Orange (assuming transaction_id is a field which increases over time, such as a receipt number):
select x.customer_id from
(
SELECT customer_id,
product_name,
row_number() OVER (
PARTITION BY customer_id ORDER BY transaction_id
) as rn
FROM default.tbl_product_sales
) x
join
(
SELECT customer_id,
product_name,
row_number() OVER (
PARTITION BY customer_id ORDER BY transaction_id
) as rn
FROM default.tbl_product_sales
) y
on x.customer_id=y.customer_id
where y.rn=x.rn+1
and x.product_name='Apple'
and y.product_name='Orange';
So, even though transaction_id may not be contiguous or predictable (i.e. a single customer might have consecutive transactions with numbers 1234, 1255, 1257, etc.), we can still use PARTITION BY and ORDER BY to assign a new row number field which is contiguous – whereby each each customer will have their transactions grouped and ordered. In the above query, rn and rn+1 represent any transaction for a given customer and the transaction immediately afterwards.
A handy feature of Hadoop Hive is the ability to use the filename and path of underlying files as columns in a view or table using the virtual Hive column INPUT__FILE__NAME. This is particularly handy in the case of external tables where some metadata about files is embedded in the location on HDFS or the filename itself.
The problem
Say we have some files sitting under a nested folder structure in HDFS:
The files each contain two columns, a string and an integer. We can create an external hive table as follows:
CREATE EXTERNAL TABLE default.test_filename
(
col0 string,
col1 int
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ' '
STORED AS TEXTFILE
LOCATION '/tmp/testonly/';
A simple select on the above table shows data from all subdirectories without any more information:
The solution – including file metadata in Hive
Hive features a virtual column INPUT__FILE__NAME which can be used to query the file location and filenames of textfiles where the actual table data is sitting:
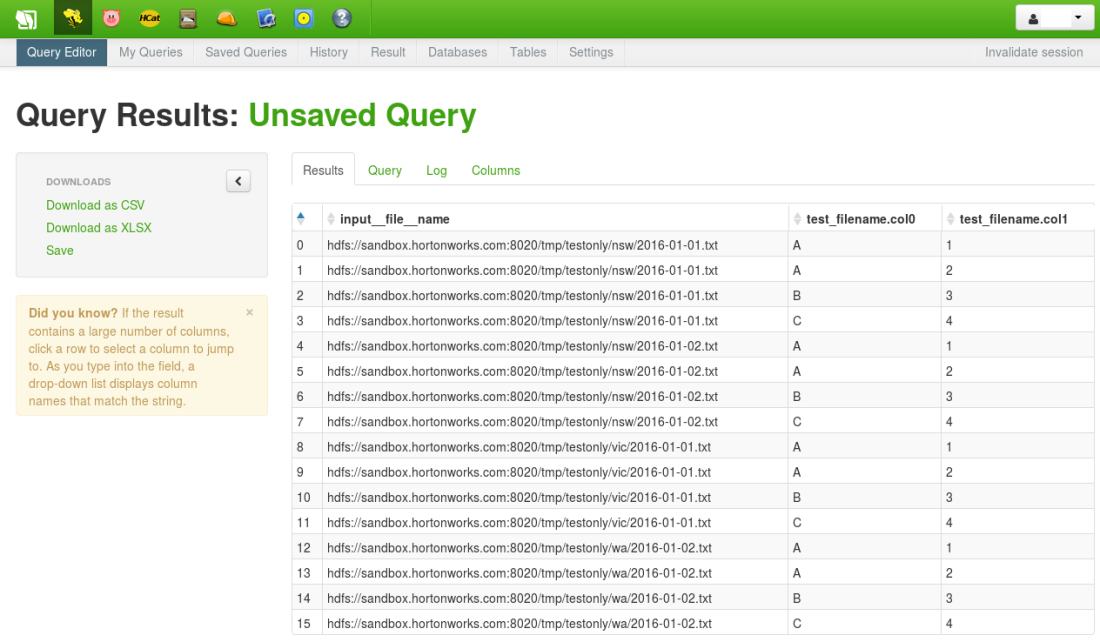
SELECT INPUT__FILE__NAME, * FROM default.test_filename;
The full HDFS path is now included as a column in each row of data (e.g. “hdfs://sandbox.hortonworks.com:8020/tmp/testonly/vic/2016-01-01.txt”):
We can go one step further and use standard Hive functions to create two new artificial columns – file_date (from the filename) and state (from the HDFS subfolder).
SELECT substring(INPUT__FILE__NAME,length(INPUT__FILE__NAME)-13,10) as file_date,
regexp_extract(INPUT__FILE__NAME, '.*/(.*)/.*.txt', 1) as state,
*
FROM default.test_filename;
Now there are two extra columns in our Hive resultset derived solely from the HDFS path of the underlying files:
Apache Hive is great for enabling SQL-like queryability over flat files. This is trivial in the case of tabular formatted files such as CSV files where we can set custom row and field delimiters out-of-the-box (e.g. Hive’s inbuilt CSV serde). Even more complex files can be read and converted to a desired row and column format using Hive’s regexp_extract() function, so long as we can operate on a single row at a time.
The problem
What if the rows we want in Hive aren’t rows in the input files? That is, we need to read the file as a whole and decode it to produce the output we want to see in Hive.
An example is the Australian Bureau of Meteorology’s ASCII Grid format. These files are fixed file formats with a header section which effectively describes how to read the file. In the data section, each data row corresponds to a row of latitude on a map (with starting coordinates identified in the header) and similarly each column defines a line of longitude. Read as a whole, the file contains a grid of readings of particular weather observations – e.g. rainfall for a given time period:
Example decoding of ASCII grid format file
To read this data in Hive it might be possible to define a table which hard-codes column values to their corresponding longitude, but this leaves the problem of reading simlarly formatted files with a different geographical granularity or different starting position on the globe. Similarly, we may struggle at the Hive query language layer to determine the appropriate latitude of a given data row in the file. This is because the header contains the required metadata as to which row in the file corresponds to a certain latitude.
To make the grid data easier to consume in Hive we may wish to transform files into a format such as this:
Geospatial data – desired tabular format
This means we can query a file by filtering on particular lat / long combinations. One way to transform the file into this format is via creating custom Hive InputFormat and Record Reader Java classes that we can use at query time.
InputFormat / RecordReader vs SerDe
A key distinction when creating custom classes to use with Hive is the following:
InputFormat and RecordReader – takes files as input – generates rows
SerDe – takes rows as input – generates columns
Here, ASCII grid formatted files cannot be de-serialised row-by-row because there is important information in the header about what each row contains (i.e. the latitude of a given row is dependent on its position in the file and also information in the header), so a SerDe is likely not the best option. Instead, an InputFormat Java class can be written to convert the input ASCII grid formatted files into the desired tabular format above, making it possibe to query via Hive via arbitrary lat / long coordinates.
Creating a custom InputFormat
An InputFormat compatible with Hive can be created by creating classes which implement and extend standard mapred library classes:
CustomTextInputFormat.java – extends FixedLengthInputFormat. Returns a CustomTextRecordReader which plugs in to Hive at runtime behind the scenes.
CustomTextRecordReader.java– implements mapred RecordReader<LongWritable, BytesWritable>. Reads and decompresses (if required) files off the Hadoop filesystem. Calls ReadASCIIGridFile to do the actual transformation.
ReadASCIIGridFile.java– contains a static class which does the transformation from input (a byte array – ASCII grid formatted) to output (a byte array – Hive row format)
Notes:
Code uses the mapred rather than mapreduce API of Hadoop, as Hive only supports mapred style InputFormat objects
CustomTextInputFormat.java sets all files to be non-splittable. This is done because a file must be read in full with its header to properly convert to the target format.
The CustomTextRecordReader copes with compressed input files by utilising the org.apache.hadoop.io.compress.CompressionCodec class to decompress any input files which are compressed. This is advantageous for ASCII grid formatted files which lend themselves well to compression (e.g. via GZIP) before being uploaded to HDFS.
Compiling the custom InputFormat
Copy text out of the above files and save to a folder on the filesystem. Build these and then and compile into a JAR file (note – a Java JDK must be installed to run the compilation, preferably the same version as the target Hadoop system is running):
Note – the classpath in the javac command assumes that necessary Hadoop library jar files are installed in certain locations. The locations mentioned are for the Hortonworks HDP 2.3.0 Sandbox VM, but can be changed to suit other versions / distributions.
Using the custom InputFormat with Hive
Run hive at the command line.
In the Hive session, add the newly created InputFormat JAR:
hive> add jar /tmp/CustomTextInputFormat.jar;
Added [/tmp/CustomTextInputFormat.jar] to class path
Added resources: [/tmp/CustomTextInputFormat.jar]
Create an external table on an HDFS directory containing ASCII grid formatted files:
hive> create external table default.test_ascii(lat1 float, long1 float, lat2 float, long2 float, measurement float)ROW FORMAT DELIMITEDFIELDS TERMINATED BY '\t'STORED AS INPUTFORMAT 'com.analyticsanvil.custominputformat.CustomTextInputFormat'OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.IgnoreKeyTextOutputFormat'LOCATION '/tmp/';
OK
Time taken: 13.192 seconds
The query returns data in the desired tabular format.
Conclusion
By creating an InputFormat Java class which reads and transforms fixed format files at the time of Hive querying, we can effectively convert data into forms better which are better suited to analytical purposes.
Similarly, writing a custom input format allows almost any data to be read by invoking a custom Java class on each mapper, translating the input into tabular format for use in Hive. In the above example ReadASCIIGridFile.java converts an ASCII grid formatted file to a long list of lat / long combinations and readings, but equally, a new Java class could be coded to read more exotic forms of input data – e.g. MP3 audio files, JPEGs or other types of binary file. So long as a developer knows how to code the translation in Java, input formats can be converted into Hive queryable tabular data on the fly and in parallel (e.g. MP3 files with timestamps and spectral / frequency analysis).
It’s worth noting, further improvements can be made to the Java code above. For example – more efficient parsing of input files (currently using regular expressions), better error checking, memory utilisation and a mechanism to combine input files for a given input split to improve performance.
Sometimes it is useful to sort data by two columns and get the maximum of both columns for each record (column A then column B).
An example is a table with a logical primary key and an additional timestamp field and a sequence number field. This could be the case, for example if data is coming from a change-data capture ETL tool, where multiple changes (inserts, updates, deletes) may be present for a single record. The timestamp could denote the batch date the ETL tool extracted the records, and within each batch there could also be a sequence number, where the highest sequence number in the highest timestamp denotes the latest version of the record.
E.g. the final record here (where f1 happens to be ‘z’) is the latest record, with a timestamp of 3 and a sequence of 2:
Hive test table with composite logical primary key and a timestamp and sequence field
Below are compared two options for achieving this in HiveQL – using two nested maximum aggregations and one which is a single pass aggregation of a named structure.
Creating a test table and data
create table if not exists test
(
pk1 string,
pk2 string,
pk3 string,
f1 string,
ts int,
sequence int
)
stored as orc;
insert into table test values (‘a’,’a’,’a’,’x’,1,1);
insert into table test values (‘a’,’a’,’a’,’y’,1,2);
insert into table test values (‘a’,’a’,’a’,’y’,1,3);
insert into table test values (‘a’,’a’,’a’,’y’,2,1);
insert into table test values (‘a’,’a’,’a’,’y’,3,1);
insert into table test values (‘a’,’a’,’a’,’z’,3,2);
select max(mysortstruct(ts,ts,sequence, sequence)).f1 from test;
Option 1 – runtime 37 seconds
set hive.execution.engine=tez;
select t1.pk1,t1.pk2,t1.pk3,t1.ts, max(t1.sequence) as maxseq
from
test t1
join
(select
pk1,pk2,pk3,max(ts) as maxts
from test
group by pk1, pk2, pk3) t2
on
t1.pk1=t2.pk1 and
t1.pk2=t2.pk2 and
t1.pk3=t2.pk3 and
t1.ts=t2.maxts
group by t1.pk1,t1.pk2,t1.pk3,t1.ts
;
Option 2 – runtime 11 seconds
set hive.execution.engine=tez;
select
pk1,
pk2,
pk3, max(named_struct(‘ts’,ts,’sequence’, sequence)).ts, max(named_struct(‘ts’,ts,’sequence’, sequence)).sequence
from test
group by pk1, pk2, pk3;
Note — max(named_struct(‘ts’,ts,’sequence’, sequence)).ts basically tells Hive “get me the latest sequence number for the latest timestamp” and then output the timestamp of that record.
The Result
Both option 1 and 2 produce the correct result —
If we look up these values in our original table we see that this corresponds to the latest record according to timestamp and then sequence. In practice, we could use this result-set to look up (via a join) non-key or attribute fields in a larger table.
It can be seen from the above via the much shorter runtime and simpler Tez execution graph that named structures (see here for Hive documentation on named structures) can help us with the timstamp + sequence use case, and any situation where we need the maximum of two columns for each logical primary key combination. This is because it gets this information in a single map-reduce pass over the dataset and does not need to operate on an intermediate dataset once the maximum of the first column has been found for each record, to then get the timestamp.
Kerberizing a Hadoop cluster enables a properly authorised user to access the cluster without entering of username / password details. For example (after running a kinit command and starting the beeline JDBC client):
Connecting to jdbc:hive2://hdplinux1.company.internal:10000/default;principal=hive/hdplinux1.company.internal@COMPANY.INTERNAL;
Enter username for jdbc:hive2://hdplinux1.company.internal:10000/default;principal=hive/hdplinux1.company.internal@COMPANY.INTERNAL;: myusername
Enter password for jdbc:hive2://hdplinux1.company.internal:10000/default;principal=hive/hdplinux1.company.internal@COMPANY.INTERNAL;: ************
Connected to: Apache Hive (version 1.2.1.2.3.0.1-3)
Driver: Hive JDBC (version 1.2.1.2.3.0.1-3)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Despite the successful login above, two errors occurred subsequently when running Hive queries.
First error (permission denied)
1: jdbc:hive2://hdplinux1.company.internal:10000/default> select a,b from c where a=1;
INFO : Tez session hasn’t been created yet. Opening session
ERROR : Failed to execute tez graph.
org.apache.tez.dag.api.SessionNotRunning: TezSession has already shutdown. Application application_1441612826389_0022 failed 2 times due to AM Container for appattempt_1441612826389_0022_000002 exited with exitCode: -1000
For more detailed output, check application tracking page:http://hdplinux1.company.internal:8088/cluster/app/application_1441612826389_0022Then, click on links to logs of each attempt.
Diagnostics: Application application_1441612826389_0022 initialization failed (exitCode=255) with output: main : command provided 0
main : run as user is hive
main : requested yarn user is hive Can’t create directory /var/log/hadoop/yarn/local/usercache/hive/appcache/application_1441612826389_0022 – Permission denied
Did not create any app directories
Failing this attempt. Failing the application.
at org.apache.tez.client.TezClient.waitTillReady(TezClient.java:678)
at org.apache.hadoop.hive.ql.exec.tez.TezSessionState.open(TezSessionState.java:205)
at org.apache.hadoop.hive.ql.exec.tez.TezTask.updateSession(TezTask.java:239)
at org.apache.hadoop.hive.ql.exec.tez.TezTask.execute(TezTask.java:137)
at org.apache.hadoop.hive.ql.exec.Task.executeTask(Task.java:160)
at org.apache.hadoop.hive.ql.exec.TaskRunner.runSequential(TaskRunner.java:88)
at org.apache.hadoop.hive.ql.Driver.launchTask(Driver.java:1653)
at org.apache.hadoop.hive.ql.Driver.execute(Driver.java:1412)
at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:1195)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1059)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1054)
at org.apache.hive.service.cli.operation.SQLOperation.runQuery(SQLOperation.java:154)
at org.apache.hive.service.cli.operation.SQLOperation.access$100(SQLOperation.java:71)
at org.apache.hive.service.cli.operation.SQLOperation$1$1.run(SQLOperation.java:206)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1657)
at org.apache.hive.service.cli.operation.SQLOperation$1.run(SQLOperation.java:218)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
Error: Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.tez.TezTask (state=08S01,code=1)
Workaround:
The above error was fixed by renaming the local application cache directory on each datanode:
su –
mv /var/log/hadoop/yarn/local/usercache/hive/appcache appcache.bak
A new appcache directory will get created when re-running the hive query. Note – this step was performed in a development cluster with no other users, so may have more harmful effects in a running cluster!
Second error (org.apache.hadoop.util.DiskChecker$DiskErrorException)
After the above workaround was applied a new error appeared when executing the Hive query:
1: jdbc:hive2://hdplinux1.company.internal:10000/default> select a,b from c where a=1;
INFO : Tez session hasn’t been created yet. Opening session
ERROR : Failed to execute tez graph.
org.apache.tez.dag.api.SessionNotRunning: TezSession has already shutdown. Application application_1441612826389_0036 failed 2 times due to AM Container for appattempt_1441612826389_0036_000002 exited with exitCode: -1000
For more detailed output, check application tracking page:http://hdplinux1.company.internal:8088/cluster/app/application_1441612826389_0036Then, click on links to logs of each attempt.
Diagnostics: Application application_1441612826389_0036 initialization failed (exitCode=255) with output: main : command provided 0
main : run as user is hive
main : requested yarn user is hive org.apache.hadoop.util.DiskChecker$DiskErrorException: Cannot create directory: /var/log/hadoop/yarn/local/usercache/hive/filecache/0/11603
at org.apache.hadoop.util.DiskChecker.checkDir(DiskChecker.java:105)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.localizer.ContainerLocalizer.download(ContainerLocalizer.java:199)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.localizer.ContainerLocalizer.localizeFiles(ContainerLocalizer.java:241)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.localizer.ContainerLocalizer.runLocalization(ContainerLocalizer.java:169)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.localizer.ContainerLocalizer.main(ContainerLocalizer.java:372)
Failing this attempt. Failing the application.
at org.apache.tez.client.TezClient.waitTillReady(TezClient.java:678)
at org.apache.hadoop.hive.ql.exec.tez.TezSessionState.open(TezSessionState.java:205)
at org.apache.hadoop.hive.ql.exec.tez.TezTask.updateSession(TezTask.java:239)
at org.apache.hadoop.hive.ql.exec.tez.TezTask.execute(TezTask.java:137)
at org.apache.hadoop.hive.ql.exec.Task.executeTask(Task.java:160)
at org.apache.hadoop.hive.ql.exec.TaskRunner.runSequential(TaskRunner.java:88)
at org.apache.hadoop.hive.ql.Driver.launchTask(Driver.java:1653)
at org.apache.hadoop.hive.ql.Driver.execute(Driver.java:1412)
at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:1195)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1059)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1054)
at org.apache.hive.service.cli.operation.SQLOperation.runQuery(SQLOperation.java:154)
at org.apache.hive.service.cli.operation.SQLOperation.access$100(SQLOperation.java:71)
at org.apache.hive.service.cli.operation.SQLOperation$1$1.run(SQLOperation.java:206)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1657)
at org.apache.hive.service.cli.operation.SQLOperation$1.run(SQLOperation.java:218)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
Error: Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.tez.TezTask (state=08S01,code=1)
Workaround:
This second error was fixed by renaming the local filecache directory on each datanode:
su –
mv /var/log/hadoop/yarn/local/usercache/hive/filecache filecache.bak
A new filecache directory will get created when re-running the hive query. Again note that the impact on a running cluster is uncertain as other jobs may be actively using files in these local cache directories.
After performing the above steps, the original hive query now reruns successfully.
Further info
Vinod Vavilapalli and Omakar Vinit Joshi from Hortonworks describe the role of the appcache and filecache directories in their post on Resource Localization in Yarn. They describe how resources are localised to Yarn application nodes for performance reasons and downloaded files may be found in different local directories depending on categorisation. For example – application specific files are found in <local-dir>/usercache/<userid>/appcache/<app-id>/ and private (user-specific) files are found in <local-dir>/usercache/<userid>/filecache .